The ForkEnrichment processor is designed to be used in conjunction with the JoinEnrichment Processor. Used together, they provide a powerful mechanism for transforming data into a separate request payload for gathering enrichment data, gathering that enrichment data, optionally transforming the enrichment data, and finally joining together the original payload with the enrichment data.
A typical dataflow for accomplishing this may look something like this:
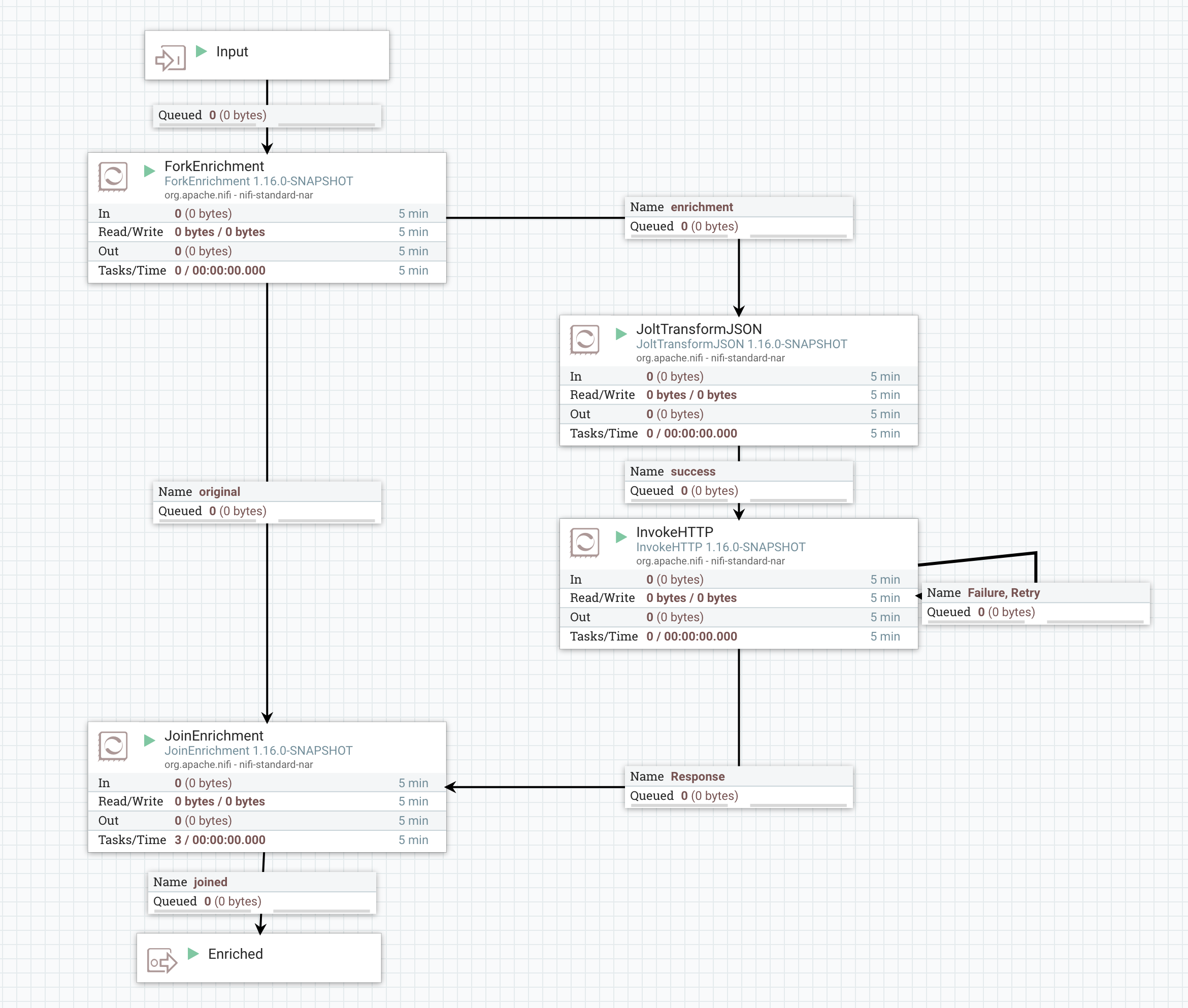
Here, we have a ForkEnrichment processor that is responsible for taking in a FlowFile and producing two copies of it: one to the "original" relationship and the other to the "enrichment" relationship. Each copy will have its own set of attributes added to it.
Next, we have the "original" FlowFile being routed to the JoinEnrichment processor, while the "enrichment" FlowFile is routed in a different direction. Each of these FlowFiles will have an attribute named "enrichment.group.id" with the same value. The JoinEnrichment processor then uses this information to correlate the two FlowFiles. The "enrichment.role" attribute will also be added to each FlowFile but with a different value. The FlowFile routed to "original" will have an enrichment.role of ORIGINAL while the FlowFile routed to "enrichment" will have an enrichment.role of ENRICHMENT.
The Processors that make up the "enrichment" path will vary from use case to use case. In this example, we use JoltTransformJSON processor in order to transform our payload from the original payload into a payload that is expected by our web service. We then use the InvokeHTTP processor in order to gather enrichment data that is relevant to our use case. Other common processors to use in this path include QueryRecord, UpdateRecord, ReplaceText, JoltTransformRecord, and ScriptedTransformRecord. It is also be a common use case to transform the response from the web service that is invoked via InvokeHTTP using one or more of these processors.
After the enrichment data has been gathered, it does us little good unless we are able to somehow combine our enrichment data back with our original payload. To achieve this, we use the JoinEnrichment processor. It is responsible for combining records from both the "original" FlowFile and the "enrichment" FlowFile.
The JoinEnrichment Processor is configured with a separate RecordReader for the "original" FlowFile and for the "enrichment" FlowFile. This means that the original data and the enrichment data can have entirely different schemas and can even be in different data formats. For example, our original payload may be CSV data, while our enrichment data is a JSON payload. Because we make use of RecordReaders, this is entirely okay. The Processor also requires a RecordWriter to use for writing out the enriched payload (i.e., the payload that contains the join of both the "original" and the "enrichment" data).
For details on how to join the original payload with the enrichment data, see the Additional Details of the JoinEnrichment Processor documentation.