The JoinEnrichment processor is designed to be used in conjunction with the ForkEnrichment Processor. Used together, they provide a powerful mechanism for transforming data into a separate request payload for gathering enrichment data, gathering that enrichment data, optionally transforming the enrichment data, and finally joining together the original payload with the enrichment data.
A typical dataflow for accomplishing this may look something like this:
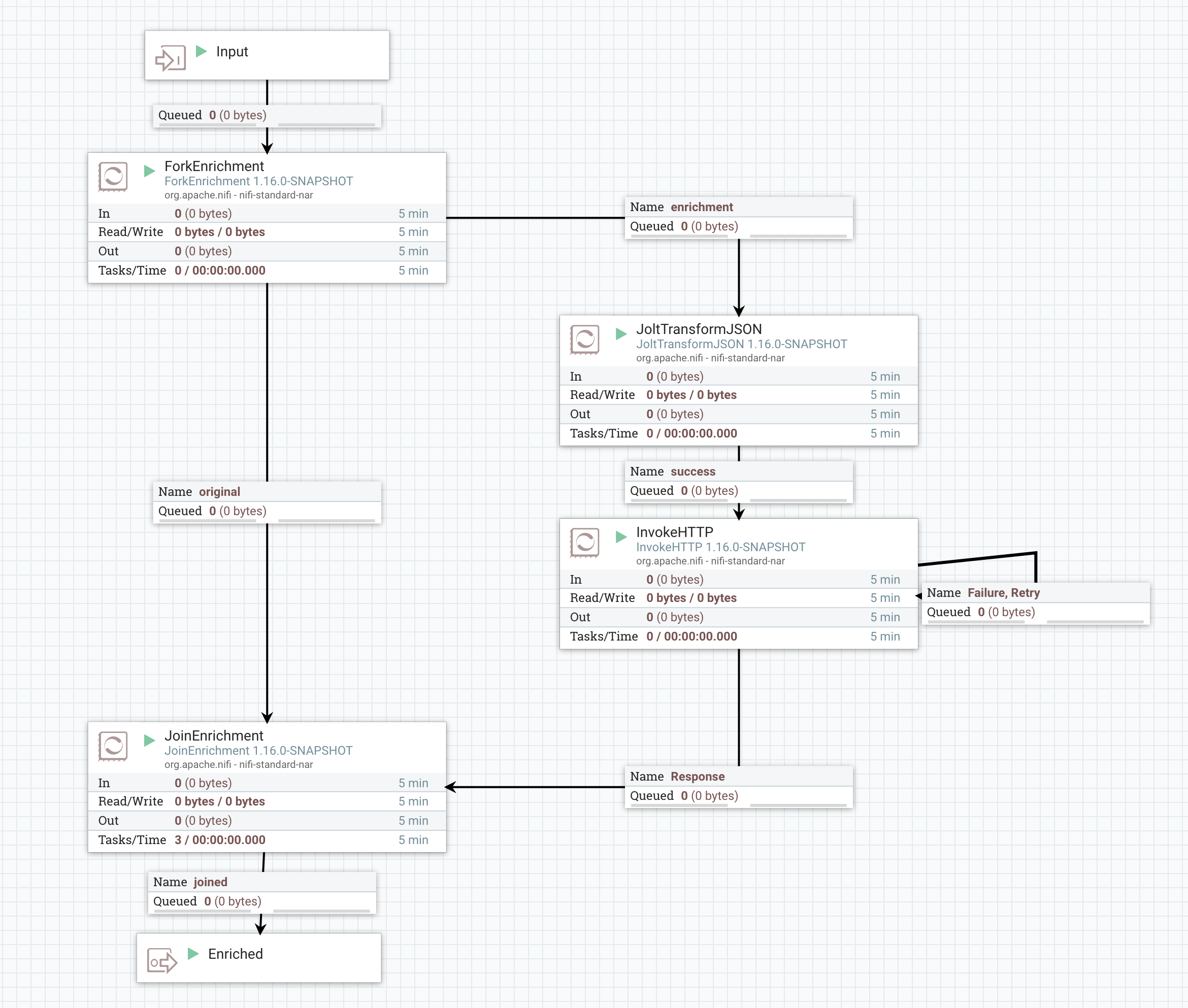
Here, we have a ForkEnrichment processor that is responsible for taking in a FlowFile and producing two copies of it: one to the "original" relationship and the other to the "enrichment" relationship. Each copy will have its own set of attributes added to it.
Next, we have the "original" FlowFile being routed to the JoinEnrichment processor, while the "enrichment" FlowFile is routed in a different direction. Each of these FlowFiles will have an attribute named "enrichment.group.id" with the same value. The JoinEnrichment processor then uses this information to correlate the two FlowFiles. The "enrichment.role" attribute will also be added to each FlowFile but with a different value. The FlowFile routed to "original" will have an enrichment.role of ORIGINAL while the FlowFile routed to "enrichment" will have an enrichment.role of ENRICHMENT.
The Processors that make up the "enrichment" path will vary from use case to use case. In this example, we use JoltTransformJSON processor in order to transform our payload from the original payload into a payload that is expected by our web service. We then use the InvokeHTTP processor in order to gather enrichment data that is relevant to our use case. Other common processors to use in this path include QueryRecord, UpdateRecord, ReplaceText, JoltTransformRecord, and ScriptedTransformRecord. It is also be a common use case to transform the response from the web service that is invoked via InvokeHTTP using one or more of these processors.
After the enrichment data has been gathered, it does us little good unless we are able to somehow combine our enrichment data back with our original payload. To achieve this, we use the JoinEnrichment processor. It is responsible for combining records from both the "original" FlowFile and the "enrichment" FlowFile.
The JoinEnrichment Processor is configured with a separate RecordReader for the "original" FlowFile and for the "enrichment" FlowFile. This means that the original data and the enrichment data can have entirely different schemas and can even be in different data formats. For example, our original payload may be CSV data, while our enrichment data is a JSON payload. Because we make use of RecordReaders, this is entirely okay. The Processor also requires a RecordWriter to use for writing out the enriched payload (i.e., the payload that contains the join of both the "original" and the "enrichment" data).
The JoinEnrichment Processor offers different strategies for how to combine the original records with the enrichment data. Each of these is explained here in some detail.
original and enrichment. Each of these will contain the nth record from the corresponding FlowFile. For example, if the original FlowFile has the following
content:
id, name, age
28021, John Doe, 55
832, Jane Doe, 22
29201, Jake Doe, 23
555, Joseph Doe, 2
id, email
28021, john.doe@nifi.apache.org
832, jane.doe@nifi.apache.org
29201, jake.doe@nifi.apache.org
[
{
"original": {
"id": 28021,
"name": "John Doe",
"age": 55
},
"enrichment": {
"id": 28021,
"email": "john.doe@nifi.apache.org"
}
}, {
"original": {
"id": 832,
"name": "Jane Doe",
"age": 22
},
"enrichment": {
"id": 832,
"email": "jane.doe@nifi.apache.org"
}
}, {
"original": {
"id": 29201,
"name": "Jake Doe",
"age": 23
},
"enrichment": {
"id": 29201,
"email": "jake.doe@nifi.apache.org"
}
}, {
"original": {
"id": 555,
"name": "Joseph Doe",
"age": 2
},
"enrichment": null
}
]
With this strategy, the first record of the original FlowFile is coupled together with the first record of the enrichment FlowFile. The second record of the original FlowFile is coupled
together with the second record of the enrichment FlowFile, and so on. If one of the FlowFiles has more records than the other, a null value will be used.
The "Insert Enrichment Fields" strategy inserts all of the fields of the "enrichment" record into the original record. The records are correlated by their index in the FlowFile. That is, the first record in the "enrichment" FlowFile is inserted into the first record in the "original" FlowFile. The second record of the "enrichment" FlowFile is inserted into the second record of the "original" FlowFile and so on.
When this strategy is selected, the "Record Path" property is required. The Record Path is evaluated against the "original" record. Consider, for example, the following content for the "original" FlowFile:
[{
"purchase": {
"customer": {
"loyaltyId": 48202,
"firstName": "John",
"lastName": "Doe"
},
"total": 48.28,
"items": [
{
"itemDescription": "book",
"price": 24.14,
"quantity": 2
}
]
}
}, {
"purchase": {
"customer": {
"loyaltyId": 5512,
"firstName": "Jane",
"lastName": "Doe"
},
"total": 121.44,
"items": [
{
"itemDescription": "book",
"price": 28.15,
"quantity": 4
}, {
"itemDescription": "inkpen",
"price": 4.42,
"quantity": 2
}
]
}
}]
[
{
"customerDetails": {
"id": 48202,
"phone": "555-555-5555",
"email": "john.doe@nifi.apache.org"
}
}, {
"customerDetails": {
"id": 5512,
"phone": "555-555-5511",
"email": "jane.doe@nifi.apache.org"
}
}
]
Let us then consider that a Record Path is used with a value of "/purchase/customer". This would yield the following results:
[{
"purchase": {
"customer": {
"loyaltyId": 48202,
"firstName": "John",
"lastName": "Doe",
"customerDetails": {
"id": 48202,
"phone": "555-555-5555",
"email": "john.doe@nifi.apache.org"
}
},
"total": 48.28,
"items": [
{
"itemDescription": "book",
"price": 24.14,
"quantity": 2
}
]
}
}, {
"purchase": {
"customer": {
"loyaltyId": 5512,
"firstName": "Jane",
"lastName": "Doe",
"customerDetails": {
"id": 5512,
"phone": "555-555-5511",
"email": "jane.doe@nifi.apache.org"
}
},
"total": 121.44,
"items": [
{
"itemDescription": "book",
"price": 28.15,
"quantity": 4
}, {
"itemDescription": "inkpen",
"price": 4.42,
"quantity": 2
}
]
}
}]
The SQL strategy provides an important capability that differs from the others, in that it allows for correlating the records in the "original" FlowFile and the records in the "enrichment" FlowFile in ways other than index based. That is, the SQL-based strategy doesn't necessarily correlate the first record of the original FlowFile with the first record of the enrichment FlowFile. Instead, it allows the records to be correlated using standard SQL JOIN expressions.
A common use case for this is to create a payload to query some web service. The response contains identifiers with additional information for enrichment, but the order of the records in the enrichment may not correspond to the order of the records in the original.
As an example, consider the following original payload, in CSV:
id, name, age
28021, John Doe, 55
832, Jane Doe, 22
29201, Jake Doe, 23
555, Joseph Doe, 2
Additionally, consider the following payload for the enrichment data:
customer_id, customer_email, customer_name, customer_since
555, joseph.doe@nifi.apache.org, Joe Doe, 08/Dec/14
832, jane.doe@nifi.apache.org, Mrs. Doe, 14/Nov/14
28021, john.doe@nifi.apache.org, John Doe, 22/Jan/22
When making use of the SQL strategy, we must provide a SQL SELECT statement to combine both our original data and our enrichment data into a single FlowFile. To do this, we treat our original FlowFile as its own table with the name "original" while we treat the enrichment data as its own table with the name "enrichment".
Given this, we might combine all of the data using a simple query such as:
SELECT o.*, e.*
FROM original o
JOIN enrichment e
ON o.id = e.customer_id
And this would provide the following output:
id, name, age, customer_id, customer_email, customer_name, customer_since
28021, John Doe, 55, 28021, john.doe@nifi.apache.org, John Doe, 22/Jan/22
832, Jane Doe, 22, 832, jane.doe@nifi.apache.org, Mrs. Doe, 14/Nov/14
555, Joseph Doe, 2, 555, joseph.doe@nifi.apache.org, Joe Doe, 08/Dec/14
Note that in this case, the record for Jake Doe was removed because we used a JOIN, rather than an OUTER JOIN. We could instead use a LEFT OUTER JOIN to ensure that we retain all records from the original FlowFile and simply provide null values for any missing records in the enrichment:
SELECT o.*, e.*
FROM original o
LEFT OUTER JOIN enrichment e
ON o.id = e.customer_id
Which would produce the following output:
id, name, age, customer_id, customer_email, customer_name, customer_since
28021, John Doe, 55, 28021, john.doe@nifi.apache.org, John Doe, 22/Jan/22
832, Jane Doe, 22, 832, jane.doe@nifi.apache.org, Mrs. Doe, 14/Nov/14
29201, Jake Doe, 23,,,,
555, Joseph Doe, 2, 555, joseph.doe@nifi.apache.org, Joe Doe, 08/Dec/14
But SQL is far more expressive than this, allowing us to perform far more powerful expressions. In this case, we probably don't want both the "id" and "customer_id" fields, or the "name" and "customer_name" fields. Let's consider, though, that the enrichment provides the customer's preferred name instead of their legal name. We might want to drop the customer_since column, as it doesn't make sense for our use case. We might then change our SQL to the following:
SELECT o.id, o.name, e.customer_name AS preferred_name, o.age, e.customer_email AS email
FROM original o
LEFT OUTER JOIN enrichment e
ON o.id = e.customer_id
And this will produce a more convenient output:
id, name, preferred_name, age, email
28021, John Doe, John Doe, 55, john.doe@nifi.apache.org
832, Jane Doe, Mrs. Doe, 22, jane.doe@nifi.apache.org
29201, Jake Doe,, 23,
555, Joseph Doe, Joe Doe, 2, joseph.doe@nifi.apache.org
So we can see tremendous power from the SQL strategy. However, there is a very important consideration that must be taken into account when using the SQL strategy.
WARNING: while the SQL strategy provides us great power, it may require significant amounts of heap. Depending on the query, the SQL engine may require buffering the contents of the entire "enrichment" FlowFile in memory, in Java's heap. Additionally, if the Processor is scheduled with multiple concurrent tasks, each of the tasks made hold the entire contents of the enrichment FlowFile in memory. This can lead to heap exhaustion and cause stability problems or OutOfMemoryErrors to occur.
There are a couple of options that will help to mitigate these concerns.
It is also worth noting that the SQL strategy may result in reordering the records within the FlowFile, so it may be necessary to use an ORDER BY clause, etc. if the ordering is important.
In addition to the warning above about using the SQL Join Strategy, there is another consideration to keep in mind in order to limit the amount of information that this Processor must keep in memory. While the Processor does not store the contents of all FlowFiles in memory, it does hold all FlowFiles' attributes in memory. As a result, the following points should be kept in mind when using this Processor.
This Processor offers several strategies that can be used for correlating data together and joining records from two different FlowFiles into a single FlowFile. However, there are times when users may require more powerful capabilities than what is offered. We might, for example, want to use the information in an enrichment record to determine whether or not to null out a value in the corresponding original records.
For such uses cases, the recommended approach is to make use of the Wrapper strategy or the SQL strategy in order to combine the original and enrichment FlowFiles into a single FlowFile. Then, connect the "joined" relationship of this Processor to the most appropriate processor for further processing the data. For example, consider that we use the Wrapper strategy to produce output that looks like this:
{
"original": {
"id": 482028,
"name": "John Doe",
"ssn": "555-55-5555",
"phone": "555-555-5555",
"email": "john.doe@nifi.apache.org"
},
"enrichment": {
"country": "UK",
"allowsPII": false
}
}
We might then use the TransformRecord processor with a JSON RecordReader and a JSON RecordSetWriter to transform this. Using Groovy, our transformation may look something like this:
import org.apache.nifi.serialization.record.Record
Record original = (Record) record.getValue("original")
Record enrichment = (Record) record.getValue("enrichment")
if (Boolean.TRUE != enrichment?.getAsBoolean("allowsPII")) {
original.setValue("ssn", null)
original.setValue("phone", null)
original.setValue("email", null)
}
return original
Which will produce for us the following output:
{
"id" : 482028,
"name" : "John Doe",
"ssn" : null,
"phone" : null,
"email" : null
}
In this way, we have used information from the enrichment record to optionally transform the original record. We then return the original record, dropping the enrichment record all together. In this way, we open up an infinite number of possibilities for transforming our original payload based on the content of the enrichment data that we have fetched based on that data.