Intro
This advanced level document is aimed at providing an in-depth look at the implementation and design decisions of NiFi. It assumes the reader has read enough of the other documentation to know the basics of NiFi.
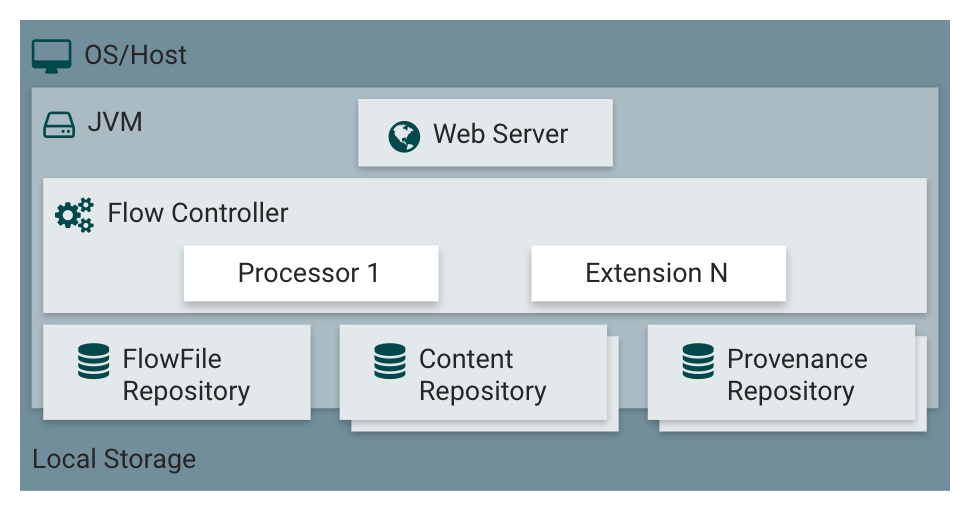
FlowFiles are at the heart of NiFi and its flow-based design. A FlowFile is a data record, which consists of a pointer to its content (payload) and attributes to support the content, that is associated with one or more provenance events. The attributes are key/value pairs that act as the metadata for the FlowFile, such as the FlowFile filename. The content is the actual data or the payload of the file. Provenance is a record of what has happened to the FlowFile. Each one of these parts has its own repository (repo) for storage.
One key aspect of the repositories is immutability. The content in the Content Repository and data within the FlowFile Repository are immutable. When a change occurs to the attributes of a FlowFile, new copies of the attributes are created in memory and then persisted on disk. When content is being changed for a given FlowFile, its original content is read, streamed through the transform, and written to a new stream. Then the FlowFile’s content pointer is updated to the new location on disk. As a result, the default approach for FlowFile content storage can be said to be an immutable versioned content store. The benefits of this are many, including: substantial reduction in storage space required for the typical complex graphs of processing, natural replay capability, takes advantage of OS caching, reduces random read/write performance hits, and is easy to reason over. The previous revisions are kept according to the archiving properties set in 'nifi.properties' file and outlined in the NiFi System Administrator’s Guide.
Repositories
There are three repositories that are utilized by NiFi. Each exists within the OS/Host’s file system and provides specific functionality. In order to fully understand FlowFiles and how they are used by the underlying system it’s important to know about these repositories. All three repositories are directories on local storage that NiFi uses to persist data.
-
The FlowFile Repository contains metadata for all the current FlowFiles in the flow.
-
The Content Repository holds the content for current and past FlowFiles.
-
The Provenance Repository holds the history of FlowFiles.
FlowFile Repository
FlowFiles that are actively being processed by the system are held in a hash map in the JVM memory (more about that in Deeper View: FlowFiles in Memory and on Disk). This makes it very efficient to process them, but requires a secondary mechanism to provide durability of data across process restarts due to a number of reasons, such as power loss, kernel panics, system upgrades, and maintenance cycles. The FlowFile Repository is a "Write-Ahead Log" (or data record) of the metadata of each of the FlowFiles that currently exist in the system. This FlowFile metadata includes all the attributes associated with the FlowFile, a pointer to the actual content of the FlowFile (which exists in the Content Repo) and the state of the FlowFile, such as which Connection/Queue the FlowFile belongs in. This Write-Ahead Log provides NiFi the resiliency it needs to handle restarts and unexpected system failures.
The FlowFile Repository acts as NiFi’s Write-Ahead Log, so as the FlowFiles are flowing through the system, each change is logged in the FlowFile Repository before it happens as a transactional unit of work. This allows the system to know exactly what step the node is on when processing a piece of data. If the node goes down while processing the data, it can easily resume from where it left off upon restart (more in-depth in Effect of System Failure on Transactions). The format of the FlowFiles in the log is a series of deltas (or changes) that happened along the way. NiFi recovers a FlowFile by restoring a “snapshot” of the FlowFile (created when the Repository is check-pointed) and then replaying each of these deltas.
A snapshot is automatically taken periodically by the system, which creates a new snapshot for each FlowFile. The system computes a new base checkpoint by serializing each FlowFile in the hash map and writing it to disk with the filename ".partial". As the checkpointing proceeds, the new FlowFile baselines are written to the ".partial" file. Once the checkpointing is done the old "snapshot" file is deleted and the ".partial" file is renamed "snapshot".
The period between system checkpoints is configurable in the 'nifi.properties' file (documented in the NiFi System Administrator’s Guide). The default is a two-minute interval.
Effect of System Failure on Transactions
NiFi protects against hardware and system failures by keeping a record of what was happening on each node at that time in their respective FlowFile Repo. As mentioned above, the FlowFile Repo is NiFi’s Write-Ahead Log. When the node comes back online, it works to restore its state by first checking for the "snapshot" and ".partial" files. The node either accepts the "snapshot" and deletes the ".partial" (if it exists), or renames the ".partial" file to "snapshot" if the "snapshot" file doesn’t exist.
If the Node was in the middle of writing content when it went down, nothing is corrupted, thanks to the Copy On Write (mentioned below) and Immutability (mentioned above) paradigms. Since FlowFile transactions never modify the original content (pointed to by the content pointer), the original is safe. When NiFi goes down, the write claim for the change is orphaned and then cleaned up by the background garbage collection. This provides a “rollback” to the last known stable state.
The Node then restores its state from the FlowFile. For a more in-depth, step-by-step explanation of the process, see NiFi’s Write-Ahead Log Implementation.
This setup, in terms of transactional units of work, allows NiFi to be very resilient in the face of adversity, ensuring that even if NiFi is suddenly killed, it can pick back up without any loss of data.
Deeper View: FlowFiles in Memory and on Disk
The term "FlowFile" is a bit of a misnomer. This would lead one to believe that each FlowFile corresponds to a file on disk, but that is not true. There are two main locations that the FlowFile attributes exist, the Write-Ahead Log that is explained above and a hash map in working memory. This hash map has a reference to all of the FlowFiles actively being used in the Flow. The object referenced by this map is the same one that is used by processors and held in connections queues. Since the FlowFile object is held in memory, all which has to be done for the Processor to get the FlowFile is to ask the ProcessSession to grab it from the queue.
When a change occurs to the FlowFile, the delta is written out to the Write-Ahead Log and the object in memory is modified accordingly. This allows the system to quickly work with FlowFiles while also keeping track of what has happened and what will happen when the session is committed. This provides a very robust and durable system.
There is also the notion of "swapping" FlowFiles. This occurs when the number of FlowFiles in a connection queue exceeds the value set in the "nifi.queue.swap.threshold" property. The FlowFiles with the lowest priority in the connection queue are serialized and written to disk in a "swap file" in batches of 10,000. These FlowFiles are then removed from the hash map mentioned above and the connection queue is in charge of determining when to swap the files back into memory. When the FlowFiles are swapped out, the FlowFile repo is notified and it keeps a list of the swap files. When the system is checkpointed the snapshot includes a section for swapped out files. When swap files are swapped back in, the FlowFiles are added back into the hash map. This swapping technique, much like the swapping performed by most Operating Systems, allows NiFi to provide very fast access to FlowFiles that are actively being processed while still allowing many millions of FlowFiles to exist in the Flow without depleting the system’s memory.
Content Repository
The Content Repository is simply a place in local storage where the content of all FlowFiles exists and it is typically the largest of the three Repositories. As mentioned in the introductory section, this repository utilizes the immutability and copy-on-write paradigms to maximize speed and thread-safety. The core design decision influencing the Content Repo is to hold the FlowFile’s content on disk and only read it into JVM memory when it’s needed. This allows NiFi to handle tiny and massive sized objects without requiring producer and consumer processors to hold the full objects in memory. As a result, actions like splitting, aggregating, and transforming very large objects are quite easy to do without harming memory.
In the same way the JVM Heap has a garbage collection process to reclaim unreachable objects when space is needed, there exists a dedicated thread in NiFi to analyze the Content repo for un-used content (more info in the " Deeper View: Deletion After Checkpointing" section). After a FlowFile’s content is identified as no longer in use it will either be deleted or archived. If archiving is enabled in 'nifi.properties' then the FlowFile’s content will exist in the Content Repo either until it is aged off (deleted after a certain amount of time) or deleted due to the Content Repo taking up too much space. The conditions for archiving and/or deleting are configured in the 'nifi.properties' file ("nifi.content.repository.archive.max.retention.period", "nifi.content.repository.archive.max.usage.percentage") and outlined in the NiFi System Administrator’s Guide. Refer to the "Data Egress" section for more information on the deletion of content.
Deeper View: Content Claim
In general, when talking about a FlowFile, the reference to its content can simply be referred to as a "pointer" to the content. Though, the underlying implementation of the FlowFile Content reference has multiple layers of complexity. The Content Repository is made up of a collection of files on disk. These files are binned into Containers and Sections. A Section is a subdirectory of a Container. A Container can be thought of as a “root directory” for the Content Repository. The Content Repository, though, can be made up of many Containers. This is done so that NiFi can take advantage of multiple physical partitions in parallel.” NiFi is then capable of reading from, and writing to, all of these disks in parallel, in order to achieve data rates of hundreds of Megabytes or even Gigabytes per second of disk throughput on a single node. "Resource Claims" are Java objects that point to specific files on disk (this is done by keeping track of the file ID, the section the file is in, and the container the section is a part of).
To keep track of the FlowFile’s contents, the FlowFile has a "Content Claim" object. This Content Claim has a reference to the Resource Claim that contains the content, the offset of the content within the file, and the length of the content. To access the content, the Content Repository drills down using to the specific file on disk using the Resource Claim’s properties and then seeks to the offset specified by the Resource Claim before streaming content from the file.
This layer of abstraction (Resource Claim) was done so that there is not a file on disk for the content of every FlowFile. The concept of immutability is key to this being possible. Since the content is never changed once it is written ("copy on write" is used to make changes), there is no fragmentation of memory or moving data if the content of a FlowFile changes. By utilizing a single file on disk to hold the content of many FlowFiles, NiFi is able to provide far better throughput, often approaching the maximum data rates provided by the disks.
Provenance Repository
The Provenance Repository is where the history of each FlowFile is stored. This history is used to provide the Data Lineage (also known as the Chain of Custody) of each piece of data. Each time that an event occurs for a FlowFile (FlowFile is created, forked, cloned, modified, etc.) a new provenance event is created. This provenance event is a snapshot of the FlowFile as it looked and fit in the flow that existed at that point in time. When a provenance event is created, it copies all the FlowFile’s attributes and the pointer to the FlowFile’s content and aggregates that with the FlowFile’s state (such as its relationship with other provenance events) to one location in the Provenance Repo. This snapshot will not change, with the exception of the data being expired. The Provenance Repository holds all of these provenance events for a period of time after completion, as specified in the 'nifi.properties' file.
Because all of the FlowFile attributes and the pointer to the content are kept in the Provenance Repository, a Dataflow Manager is able to not only see the lineage, or processing history, of that piece of data, but is also able to later view the data itself and even replay the data from any point in the flow. A common use-case for this is when a particular down-stream system claims to have not received the data. The data lineage can show exactly when the data was delivered to the downstream system, what the data looked like, the filename, and the URL that the data was sent to – or can confirm that the data was indeed never sent. In either case, the Send event can be replayed with the click of a button (or by accessing the appropriate HTTP API endpoint) in order to resend the data only to that particular downstream system. Alternatively, if the data was not handled properly (perhaps some data manipulation should have occurred first), the flow can be fixed and then the data can be replayed into the new flow, in order to process the data properly.
Keep in mind, though, that since Provenance is not copying the content in the Content Repo, and just copying the FlowFile’s pointer to the content, the content could be deleted before the provenance event that references it is deleted. This would mean that the user would no longer able to see the content or replay the FlowFile later on. However, users are still able to view the FlowFile’s lineage and understand what happened to the data. For instance, even though the data itself will not be accessible, the user is still able to see the unique identifier of the data, its filename (if applicable), when it was received, where it was received from, how it was manipulated, where it was sent, and so on. Additionally, since the FlowFile’s attributes are made available, a Dataflow Manager is able to understand why the data was processed in the way that it was, providing a crucial tool for understanding and debugging the dataflow.
| Since provenance events are snapshots of the FlowFile, as it exists in the current flow, changes to the flow may impact the ability to replay provenance events later on. For example, if a Connection is deleted from the flow, the data cannot be replayed from that point in the flow, since there is now nowhere to enqueue the data for processing. |
For a look at the design decisions behind the Provenance Repository check out Persistent Provenance Repository Design.
Deeper View: Provenance Log Files
Each provenance event has two maps, one for the attributes before the event and one for the updated attribute values. In general, provenance events don’t store the updated values of the attributes as they existed when the event was emitted, but instead, the attribute values when the session is committed. The events are cached and saved until the session is committed and once the session is committed the events are emitted with the attributes associated with the FlowFile when the session is committed. The exception to this rule is the "SEND" event, in which case the event contains the attributes as they existed when the event was emitted. This is done because if the attributes themselves were also sent, it is important to have an accurate account of exactly what information was sent.
As NiFi is running, there is a rolling group of 16 provenance log files. As provenance events are emitted they are written to one of the 16 files (there are multiple files to increase throughput). The log files are periodically rolled over (the default timeframe is every 30 seconds). This means the newly created provenance events start writing to a new group of 16 log files and the original ones are processed for long term storage. First the rolled over logs are merged into one file. Then the file is optionally compressed (determined by the "nifi.provenance.repository.compress.on.rollover" property). Lastly the events are indexed using Lucene and made available for querying. This batched approach for indexing means provenance events aren’t available immediately for querying but in return this dramatically increases performance because committing a transaction and indexing are very expensive tasks.
A separate thread handles the deletion of provenance logs. The two conditions admins can set to control the deletion of provenance logs is the max amount of disk space it can take up and the max retention duration for the logs. The thread sorts the repo by the last modified date and deletes the oldest file when one of the conditions is exceeded.
The Provenance Repo is a Lucene index that is broken into multiple shards. This is done for multiple reasons. Firstly, Lucene uses a 32-bit integer for the document identifier so the maximum number of documents supported by Lucene without sharding is limited. Second, if we know the time range for each shard, it makes it easy to search with multiple threads. Also, this sharding also allows for more efficient deletion. NiFi waits until all events in a shard are scheduled for deletion before deleting the entire shard from disk. This makes it so we do not have to update the Lucene index when we delete.
General Repository Notes
Multiple Physical Storage Points
For the Provenance and Content repos, there is the option to stripe the information across multiple physical partitions. An admin would do this if they wanted to federate reads and writes across multiple disks. The repo (Content or Provenance) is still one logical store but writes will be striped across multiple volumes/partitions automatically by the system. The directories are specified in the 'nifi.properties' file.
Best Practice
It is considered a best practice to analyze the contents of a FlowFile as few times as possible and instead extract key information from the contents into the attributes of the FlowFile; then read/write information from the FlowFile attributes. One example of this is the ExtractText processor, which extracts text from the FlowFile Content and puts it as an attribute so other processors can make use of it. This provides far better performance than continually processing the entire content of the FlowFile, as the attributes are kept in-memory and updating the FlowFile repository is much faster than updating the Content repository, given the amount of data stored in each.
Life of a FlowFile
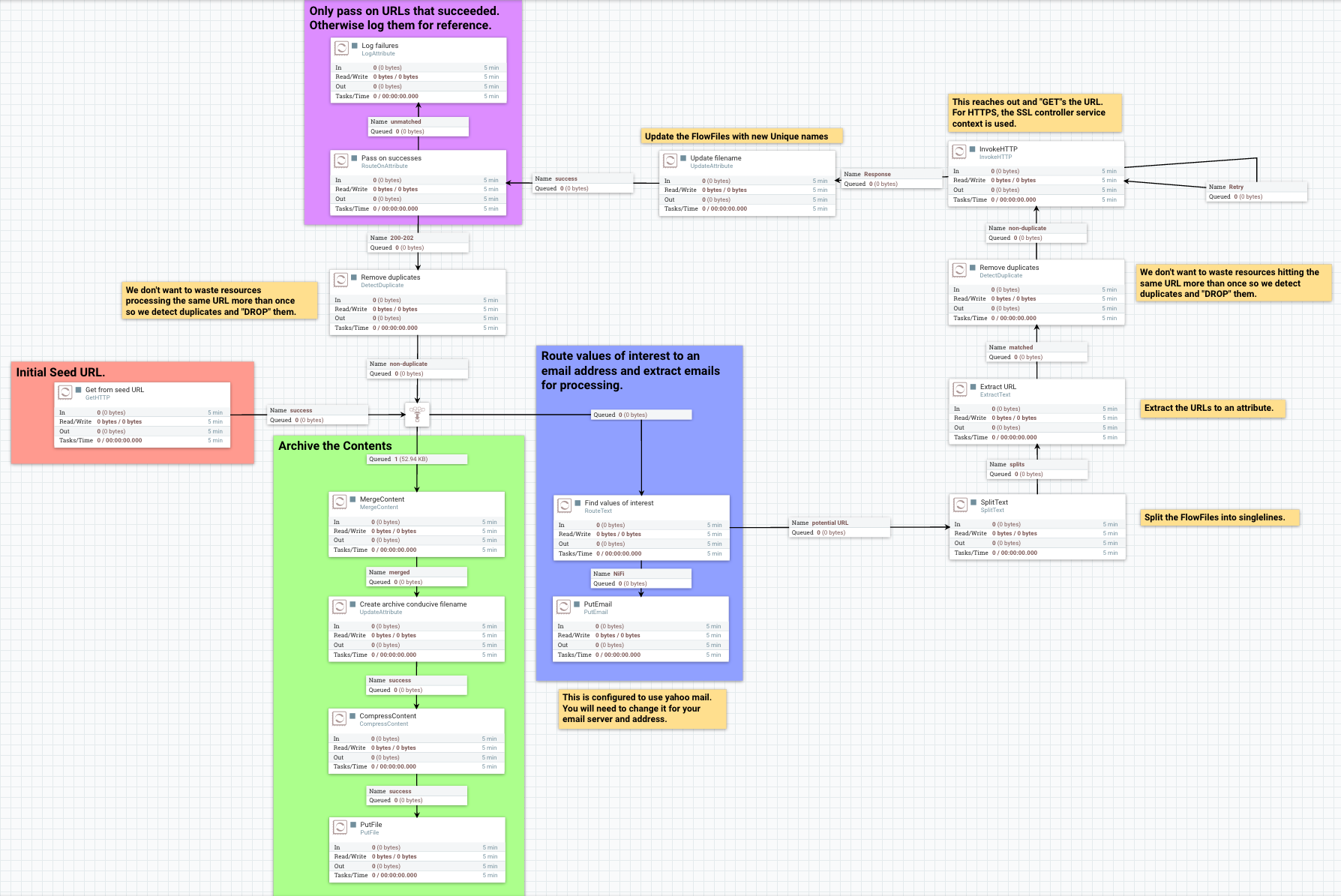
To better understand how the repos interact with one another, the underlying functionality of NiFi, and the life of a FlowFile; this next section will include examples of a FlowFile at different points in a real flow. The flow is a template called "WebCrawler.xml" and is available here: https://cwiki.apache.org/confluence/display/NIFI/Example+Dataflow+Templates.
At a high level, this template reaches out to a seed URL configured in the GetHTTP processor, then analyzes the response using the RouteText processor to find instances of a keyword (in this case "nifi"), and potential URLs to hit. Then InvokeHTTP executes a HTTP Get request using the URLs found in the original seed web page. The response is routed based on the status code attribute and only 200-202 status codes are routed back to the original RouteText processor for analysis.
The flow also detects duplicate URLs and prevents processing them again, emails the user when keywords are found, logs all successful HTTP requests, and bundles up the successful requests to be compressed and archived on disk.
| To use this flow you need to configure a couple options. First a DistributedMapCacheServer controller service must be added with default properties. At the time of writing there was no way to explicitly add the controller service to the template and since no processors reference the service it is not included. Also to get emails, the PutEmail processor must be configured with your email credentials. Finally, to use HTTPS the StandardSSLContextService must be configured with proper key and trust stores. Remember that the truststore must be configured with the proper Certificate Authorities in order to work for websites. The command below is an example of using the "keytool" command to add the default Java 1.8.0_60 CAs to a truststore called myTrustStore: keytool -importkeystore -srckeystore /Library/Java/JavaVirtualMachines/jdk1.8.0_60.jdk/Contents/Home/jre/lib/security/cacerts -destkeystore myTrustStore |
WebCrawler Template
| It is not uncommon for bulletins with messages such as "Connection timed out" to appear on the InvokeHttp processor due to the random nature of web crawling. |
Data Ingress
A FlowFile is created in the system when a producer processor invokes "ProcessSession.create()" followed by an appropriate call to the ProvenanceReporter. The "ProcessSession.create()" call creates an empty FlowFile with a few core attributes (filename, path and uuid for the standard process session) but without any content or lineage to parents (the create method is overloaded to allow parameters for parent FlowFiles). The producer processor then adds the content and attributes to the FlowFile.
ProvenanceReporter is used to emit the Provenance Events for the FlowFile. If the file is created by NiFi from data not received by an external entity then a "CREATE" event should be emitted. If instead the data was created from data received from an external source then a "RECEIVE" event should be emitted. The Provenance Events are made using "ProvenanceReporter.create()" and "ProvenanceReporter.receive()" respectively.
In our WebCrawler flow, the GetHTTP processor creates the initial FlowFile using "ProcessSession.create()" and records the receipt of data using "ProvenanceReporter.receive()". This method call also provides the URL from which the data was received, how long it took the transfer the data, and any FlowFile attributes that were added to the FlowFile. HTTP Headers, for instance, can be added as FlowFile attributes.
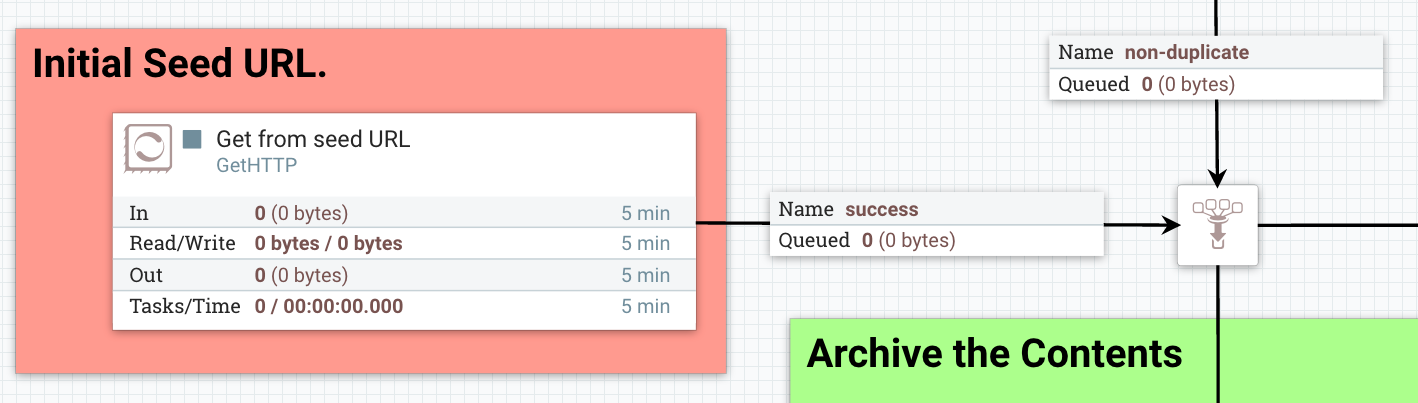
Pass by Reference
An important aspect of flow-based programming is the idea of resource-constrained relationships between the black boxes. In NiFi these are queues and processors respectively. FlowFiles are routed from one processor to another through queues simply by passing a reference to the FlowFile (similar to the "Claim Check" pattern in EIP).
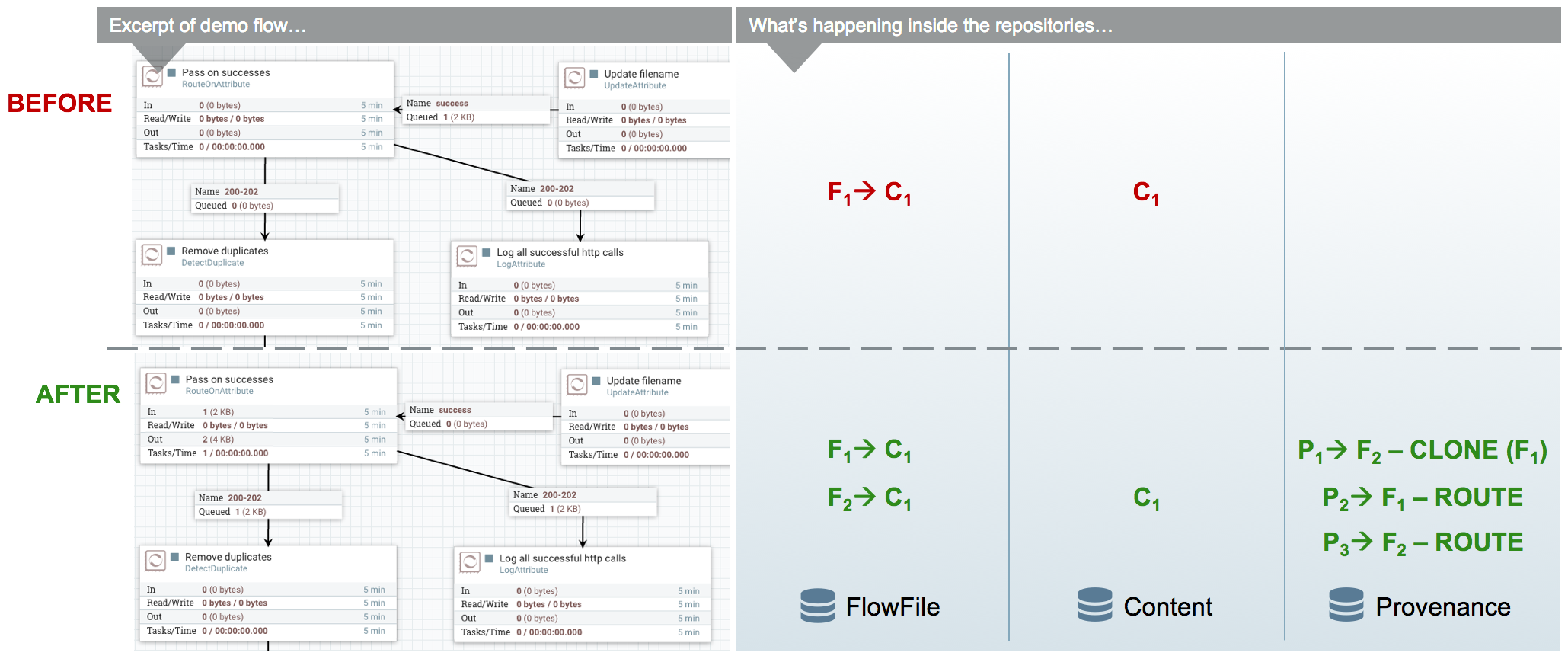
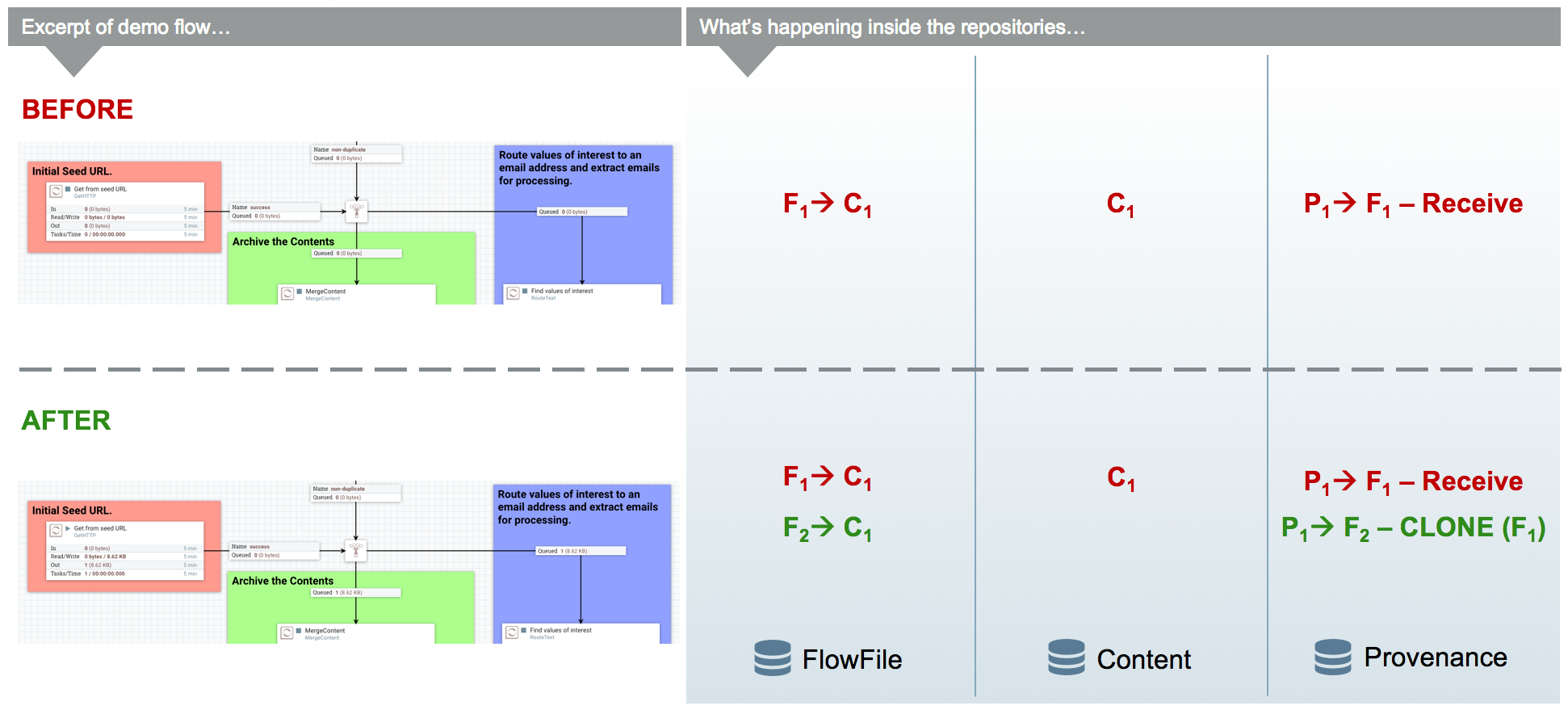
In the WebCrawler flow, the InvokeHTTP processor reaches out to the URL with an HTTP GET request and adds a status code attribute to the FlowFile depending on what the response was from the HTTP server. After updating the FlowFile’s filename (in the UpdateAttribute processor after InvokeHttp) there is a RouteOnAttribute processor that routes FlowFiles with successful status code attributes to two different processors. Those that are unmatched are "DROPPED" (See the Data Egress section) by the RouteOnAttribute Processor, because it is configured to Auto-Terminate any data that does not match any of the routing rules. Coming in to the RouteOnAttribute processor there is a FlowFile (F1) that contains the status code attribute and points to the Content (C1). There is a provenance event that points to C1 and includes a snapshot of F1 but is omitted to better focus on the routing. This information is located in the FlowFile, Content and Provenance Repos respectively.
After the RouteOnAttribute processor examines the FlowFile’s status code attribute it determines that it should be routed to two different locations. The first thing that happens is the processor clones the FlowFile to create F2. This copies all of the attributes and the pointer to the content. Since it is merely routing and analyzing the attributes, the content does not change. The FlowFiles are then added to the respective connection queue to wait for the next processor to retrieve them for processing.
The ProvenanceReporter documents the changes that occurred, which includes a CLONE and two ROUTE events. Each of these events has a pointer to the relevant content and contains a copy of the respective FlowFiles in the form of a snapshot.
Extended Routing Use-cases
In addition to routing FlowFiles based on attributes, some processors also route based on content. While it is not as efficient, sometimes it is necessary because you want to split up the content of the FlowFile into multiple FlowFiles.
One example is the SplitText processor. This processor analyzes the content looking for end line characters and creates new FlowFiles containing a configurable number of lines. The Web Crawler flow uses this to split the potential URLs into single lines for URL extraction and to act as requests for InvokeHttp. One benefit of the SplitText processor is that since the processor is splitting contiguous chunks (no FlowFile content is disjoint or overlapping) the processor can do this routing without copying any content. All it does is create new FlowFiles, each with a pointer to a section of the original FlowFile’s content. This is made possible by the content demarcation and split facilities built into the NiFi API. While not always feasible to split in this manner when it is feasible the performance benefits are considerable.
RouteText is a processor that shows why copying content can be needed for certain styles of routing. This processor analyzes each line and routes it to one or more relationships based on configurable properties. When more than one line gets routed to the same relationship (for the same input FlowFile), those lines get combined into one FlowFile. Since the lines could be disjoint (lines 1 and 100 route to the same relationship) and one pointer cannot describe the FlowFile’s content accurately, the processor must copy the contents to a new location. For example, in the Web Crawler flow, the RouteText processor routes all lines that contain "nifi" to the "NiFi" relationship. So when there is one input FlowFile that has "nifi" multiple times on the web page, only one email will be sent (via the subsequent PutEmail processor).
Funnels
The funnel is a component that takes input from one or more connections and routes them to one or more destinations. The typical use-cases of which are described in the User Guide. Regardless of use-case, if there is only one processor downstream from the funnel then there are no provenance events emitted by the funnel and it appears to be invisible in the Provenance graph. If there are multiple downstream processors, like the one in WebCrawler, then a clone event occurs. Referring to the graphic below, you can see that a new FlowFile (F2) is cloned from the original FlowFile (F1) and, just like the Routing above, the new FlowFile just has a pointer to the same content (the content is not copied).
From a developer point of view, you can view a Funnel just as a very simple processor. When it is scheduled to run, it simply does a "ProcessSession.get()" and then "ProcessSession.transfer()" to the output connection . If there is more than one output connection (like the example below) then a "ProcessSession.clone()" is run. Finally a "ProcessSession.commit()" is called, completing the transaction.
Copy on Write
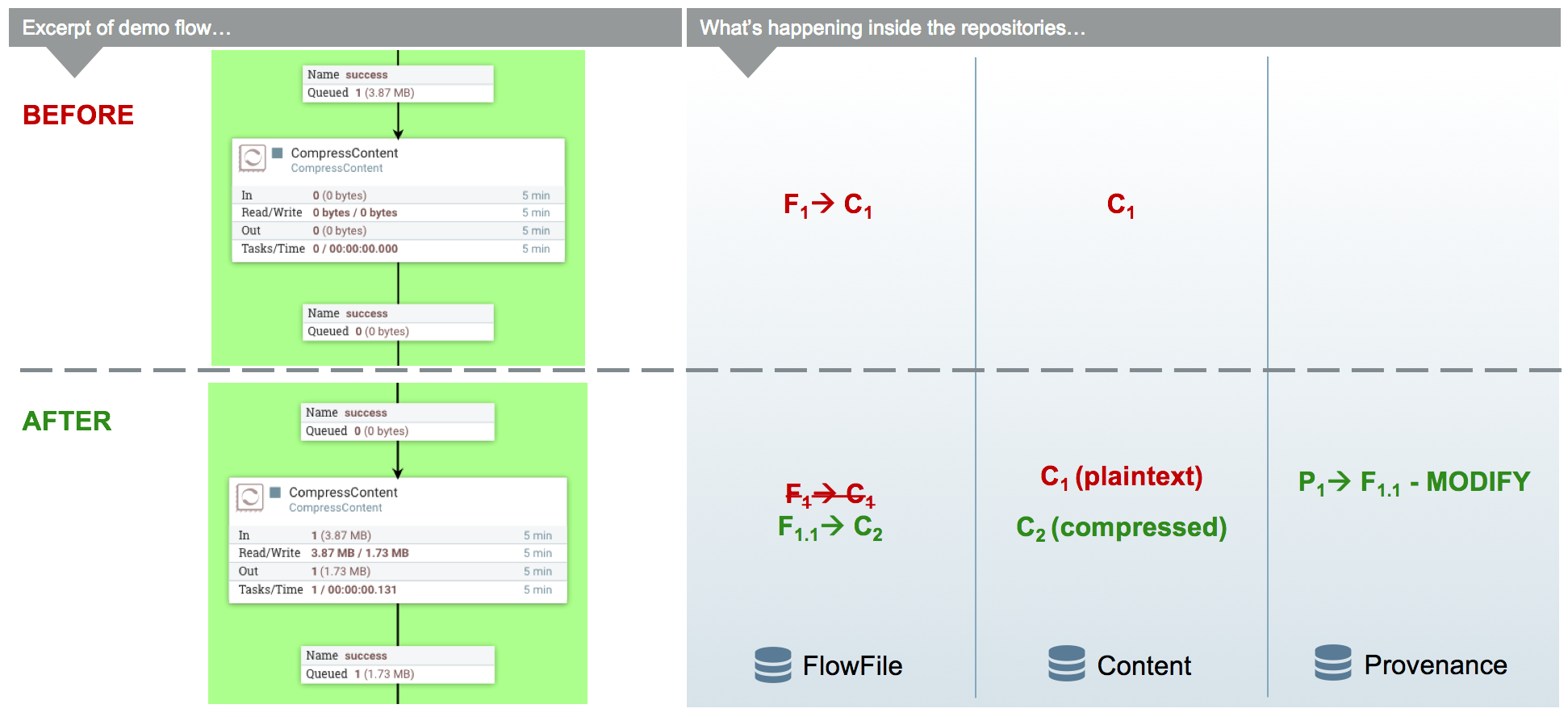
In the previous example, there was only routing but no changes to the content of the FlowFile. This next example focuses on the CompressContent processor of the template that compresses the bundle of merged FlowFiles containing webpages that were queued to be analyzed.
In this example, the content C1 for FlowFile F1 is being compressed in the CompressContent processor. Since C1 is immutable and we want a full re-playable provenance history we can’t just overwrite C1. In order to "modify" C1 we do a "copy on write", which we accomplish by modifying the content as it is copied to a new location within the content repository. When doing so, FlowFile reference F1 is updated to point to the new compressed content C2 and a new Provenance Event P2 is created referencing the new FlowFile F1.1. Because the FlowFile repo is immutable, instead of modifying the old F1, a new delta (F1.1) is created. Previous provenance events still have the pointer to the Content C1 and contain old attributes, but they are not the most up-to-date version of the FlowFile.
| For the sake of focusing on the Copy on Write event, the FlowFile’s (F1) provenance events leading up to this point are omitted. |
Extended Copy on Write Use-case
A unique case of Copy on Write is the MergeContent processor. Just about every processor only acts on one FlowFile at a time. The MergeContent processor is unique in that it takes in multiple FlowFiles and combines them into one. Currently, MergeContent has multiple different Merge Strategies but all of them require the contents of the input FlowFiles to be copied to a new merged location. After MergeContent finishes, it emits a provenance event of type "JOIN" that establishes that the given parents were joined together to create a new child FlowFile.
Updating Attributes
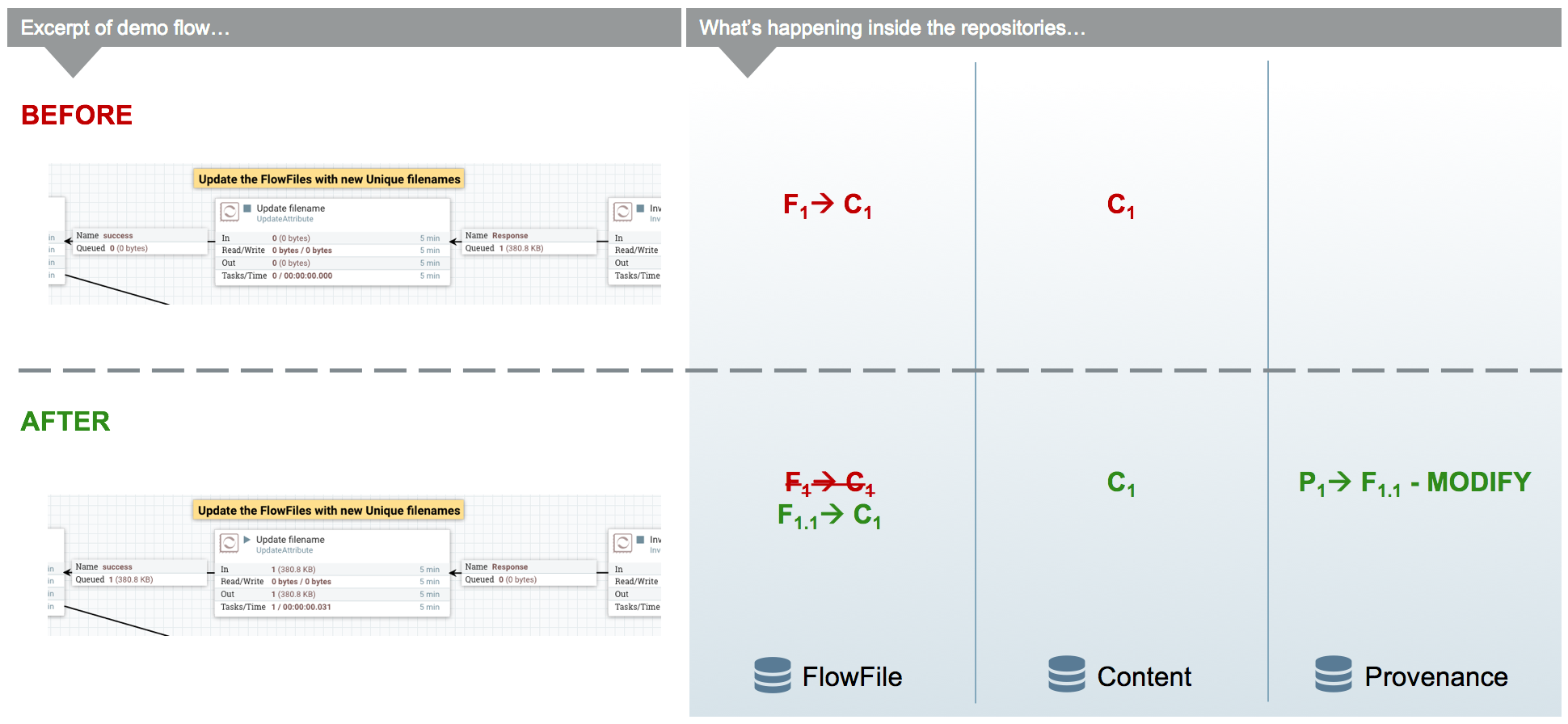
Working with a FlowFile’s attributes is a core aspect of NiFi. It is assumed that attributes are small enough to be entirely read into local memory every time a processor executes on it. So it is important that they are easy to work with. As attributes are the core way of routing and processing a FlowFile, it is very common to have processors that just change a FlowFile’s attributes. One such example is the UpdateAttribute processor. All the UpdateAttribute processor does is change the incoming FlowFile’s attributes according to the processor’s properties.
Taking a look at the diagram, before the processor there is the FlowFile (F1) that has attributes and a pointer to the content (C1). The processor updates the FlowFile’s attributes by creating a new delta (F1.1) that still has a pointer to the content (C1). An “ATTRIBUTES_MODIFIED” provenance event is emitted when this happens.
In this example, the previous processor (InvokeHTTP) fetched information from a URL and created a new response FlowFile with a filename attribute that is the same as the request FlowFile. This does not help describe the response FlowFile, so the UpdateAttribute processor modifies the filename attribute to something more relevant (URL and transaction ID).
| For the sake of focusing on the ATTRIBUTES_MODIFIED event the FlowFile’s (F1) provenance events leading up to this point are omitted. |
Typical Use-case Note
In addition to adding arbitrary attributes via UpdateAttribute, extracting information from the content of a FlowFile into the attributes is a very common use-case. One such example in the Web Crawler flow is the ExtractText processor. We cannot use the URL when it is embedded within the content of the FlowFile, so we much extract the URL from the contents of the FlowFile and place it as an attribute. This way we can use the Expression Language to reference this attribute in the URL Property of InvokeHttp.
Data Egress
Eventually data in NiFi will reach a point where it has either been loaded into another system and we can stop processing it, or we filtered the FlowFile out and determined we no longer care about it. Either way, the FlowFile will eventually be "DROPPED". "DROP" is a provenance event meaning that we are no longer processing the FlowFile in the Flow and it is available for deletion. It remains in the FlowFile Repository until the next repository checkpoint. The Provenance Repository keeps the Provenance events for an amount of time stated in 'nifi.properties' (default is 24 hours). The content in the Content Repo is marked for deletion once the FlowFile leaves NiFi and the background checkpoint processing of the Write-Ahead Log to compact/remove occurs. That is unless another FlowFile references the same content or if archiving is enabled in 'nifi.properties'. If archiving is enabled, the content exists until either the max percentage of disk is reached or max retention period is reached (also set in 'nifi.properties').
Deeper View: Deletion After Checkpointing
| This section relies heavily on information from the "Deeper View: Content Claim" section above. |
Once the “.partial” file is synchronized with the underlying storage mechanism and renamed to be the new snapshot (detailed in the FlowFile Repo section) there is a callback to the FlowFile Repo to release all the old content claims (this is done after checkpointing so that content is not lost if something goes wrong). The FlowFile Repo knows which Content Claims can be released and notifies the Resource Claim Manager. The Resource Claim Manager keeps track of all the content claims that have been released and which resource claims are ready to be deleted (a resource claim is ready to be deleted when there are no longer any FlowFiles referencing it in the flow).
Periodically, the Content Repo asks the Resource Claim Manager which Resource Claims can be cleaned up. The Content Repo then makes the decision whether the Resource Claims should be archived or deleted (based on the value of the "nifi.content.repository.archive.enabled" property in the 'nifi.properties' file). If archiving is disabled, then the file is simply deleted from the disk. Otherwise, a background thread runs to see when archives should be deleted (based on the conditions above). This background thread keeps a list of the 10,000 oldest content claims and deletes them until below the necessary threshold. If it runs out of content claims it scans the repo for the oldest content to re-populate the list. This provides a model that is efficient in terms of both Java heap utilization as well as disk I/O utilization.
Associating Disparate Data
One of the features of the Provenance Repository is that it allows efficient access to events that occur sequentially. A NiFi Reporting Task could then be used to iterate over these events and send them to an external service. If other systems are also sending similar types of events to this external system, it may be necessary to associate a NiFi FlowFile with another piece of information. For instance, if GetSFTP is used to retrieve data, NiFi refers to that FlowFile using its own, unique UUID. However, if the system that placed the file there referred to the file by filename, NiFi should have a mechanism to indicate that these are the same piece of data. This is accomplished by calling the ProvenanceReporter.associate() method and providing both the UUID of the FlowFile and the alternate name (the filename, in this example). Since the determination that two pieces of data are the same may be flow-dependent, it is often necessary for the DataFlow Manager to make this association. A simple way of doing this is to use the UpdateAttribute processor and configure it to set the "alternate.identifier" attribute. This automatically emits the "associate" event, using whatever value is added as the “alternate.identifier” attribute.
Closing Remarks
Utilizing the copy-on-write, pass-by-reference, and immutability concepts in conjunction with the three repositories, NiFi is a fast, efficient, and robust enterprise dataflow platform. This document has covered specific implementations of pluggable interfaces. These include the Write-Ahead Log based implementation of the FlowFile Repository, the File based Provenance Repository, and the File based Content Repository. These implementations are the NiFi defaults but are pluggable so that, if needed, users can write their own to fulfill certain use-cases.
Hopefully, this document has given you a better understanding of the low-level functionality of NiFi and the decisions behind them. If there is something you wish to have explained more in depth or you feel should be included please feel free to send an email to the Apache NiFi Developer mailing list (dev@nifi.apache.org).